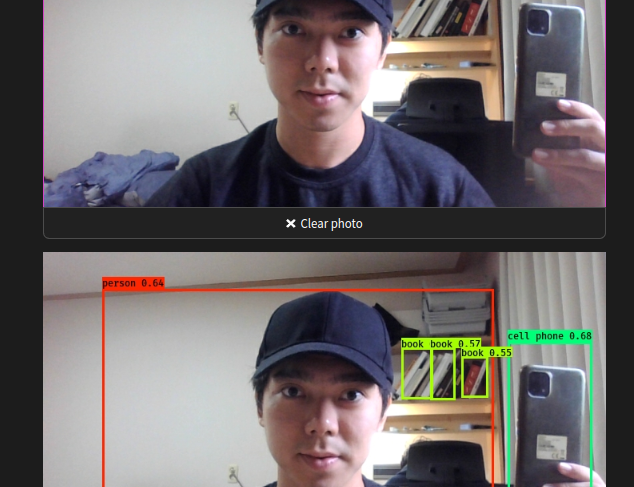
Physics-aware Multi-Object 3D Scene Reconstruction (in Progress)
Recently, research in 3D reconstruction shifts from achieving consistency in mere appearance and geometry to attaining physically plausible models of the scene or the object. For this problem, while test-time optimization approaches takes hours to optimize reasonble physical parameters of even a single object, the generalizability of feed-forward approaches is too limited. We are currently striving to overcome the shortcomings of both approaches and provide a simulation pipeline that is easily generalizable.